前言
系列将简单介绍一下IE的相关内容,篇幅和自己的认知有限,其中必然有不足之处,如果有写得不对的地方欢迎大家指出。
文章布局:每篇文章最多含有3个部分,这3个部分介绍的是相关内容,但并不一定是同一系列的东西,望见谅。
第一部分通常是背景介绍
第二部分是总结性的描述
第三部分则是详细介绍或者实践。
I.1 Internet Explorer的历史变迁
在记忆中,从1999年开始接触网络,从那时跟随着Windows 95一起而来的Internet Explorer 4算起,微软已经发布了8个不同版本的IE了(如果Spartan姑且算做是Internet Explorer 12的话)。这之中Internet Explorer(以下简称IE)都做了哪些变更呢?里程碑可以数一数:
·IE1、IE2(1995年):家族中最简单的“浏览器”,只支持静态的页面,现在你能用得到的许多功能,它都不支持。现在你用到的许多功能他却有了雏形。

·IE3 (1996年):对早期版本的改进,支持了ActiveX控件,支持了JavaScript和VBScript(当时称为Microsoft JScript和Microsoft VBScript,不为啥,就因为商标问题)。而且从这时开始就支持WebBrowser这个被人熟知的ActiveX控件了,这保证了浏览器的可重用性。

·IE4(1997年):引入了DHTML功能,支持数据绑定,同时增强了WebBrowser的功能,添加了一些新特性,增加了侧边栏,以及BHO。
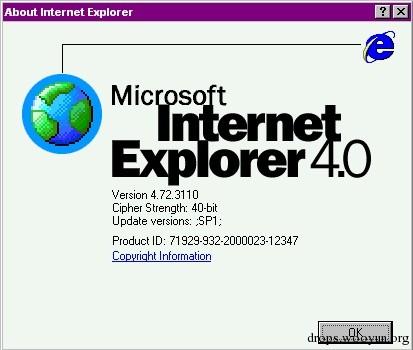
·IE5(1999年):随着Windows 98一起发售,支持持久会话,紧接着诞生了XMLHttpRequest,促使了AJAX的发展(尽管此时AJAX一词都还没诞生……),引入了HTA,还有自动填表等功能。IE 5.5版本起还支持了128位的加密。
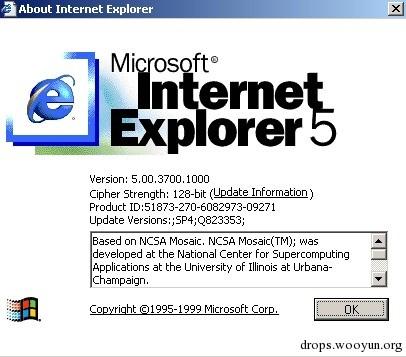
·IE6(2001年):紧接着Windows XP一起发售,可能是给大家留下印象最深刻的浏览器,在2002-2003年中,IE6的市场份额达到了90%,IE全家族的市场份额达到了95%。 同时,这也是最饱受诟病的浏览器,因为它的安全问题实在是很严重。这一版本中增加的大多是网页渲染相关的,例如CSS1 、DOM1等的部分支持。
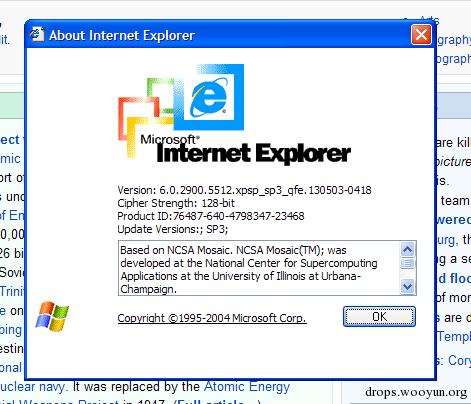
·IE7(2006年)、IE8(2009年):IE6市场份额被火狐抢走之后微软推出的新版本浏览器,这两个版本大部分都是性能调整和渲染修整以及增强。
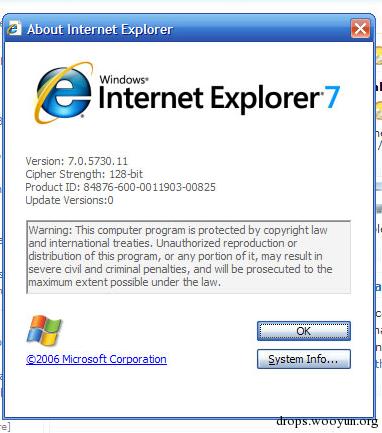
·IE9(2011年),稳定版本,性能提升和HTML5支持,多进程支持,这使得网页假死或者崩溃时不会影响到其他页面。
不放截图了,IE9之后这些版本大家很容易就能搜到。
·IE10(2011年)/IE11(2013年),性能较大的增强了,以及渲染以及兼容增强,增加DNT支持,IE10开始性能真的已经和之前有较大的不同了,但是顶着IE的名号,还是承受着IE6带来的深刻影响。
·Spartan(2015年),代号IE12。整合了语音助手,性能提升等,估计微软此举也是要丢掉IE的牌子另起炉灶,从程序上看,至少它确实和IE用的不是同一套DLL库了。
I.2 IE的构成
在早期的单进程IE中,IE的结构大致如:

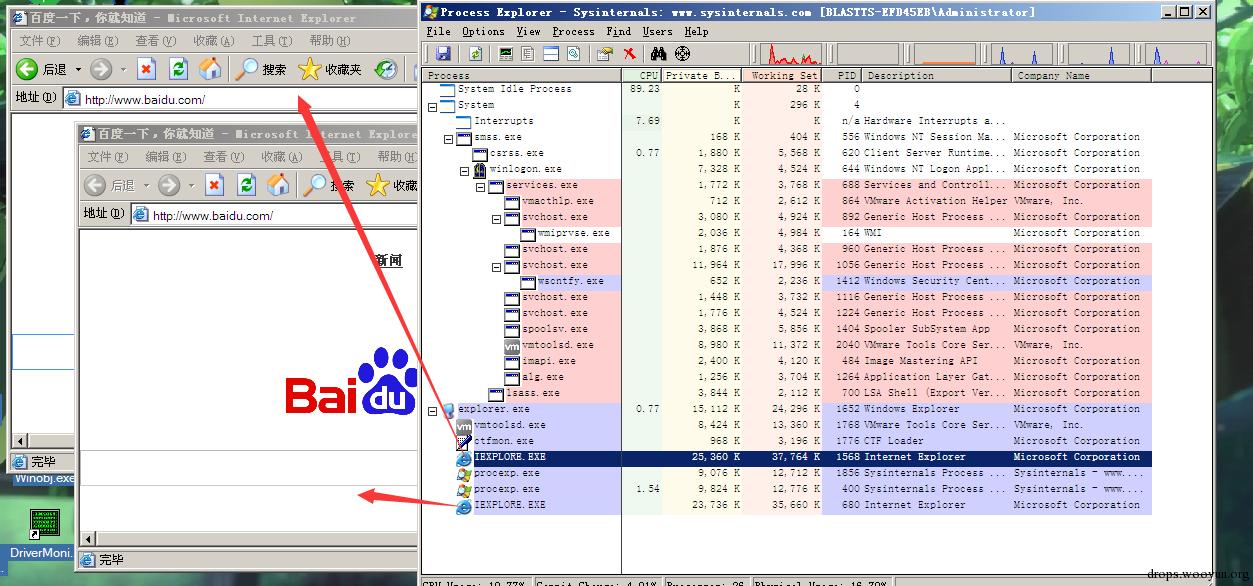
图:以 IE6 为代表的单进程无 tab 模式
随着多进程的引入,IE 的网页部分结构还是类似这样,但是界面宿主已经有变化了,看起来像是:

请注意上图中外壳网页分属于不同进程。
在IE7中,一个进程中可以运行一组网页窗口了,但是新窗口不代表在新进程里面运行。(比如你用Ctrl+N新建窗口,其实它还是在当前进程里面创建的),可以自己安装一个IE7来试验,如果没用过的话看我这个描述应该会很奇怪。开启了保护模式的进程会运行在低完整性级别下,通过一个代理进程来进行通信。
简化的进程模型如下:


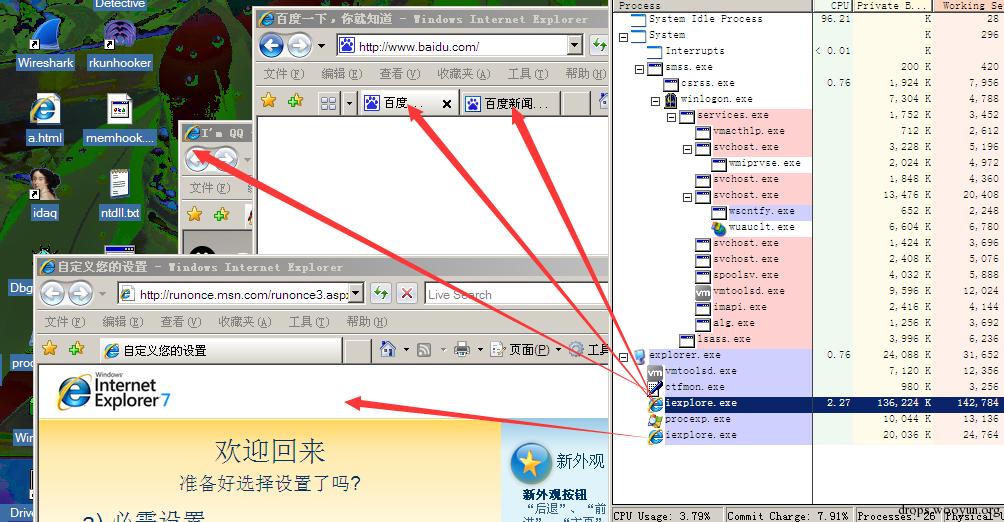
图:IE7 的进程模式
在 IE8 中,微软引入了 IE8 松散耦合进程框架(LCIE),它使用 Jobs 来限制进程权限(吐槽 一下,自己试着用Jobs控制权限,实际应用在IE中的话深知不易,微软也是下了不少功夫), 这个时候,开启了保护模式与未开启保护模式的 IE8 的结构类似于:

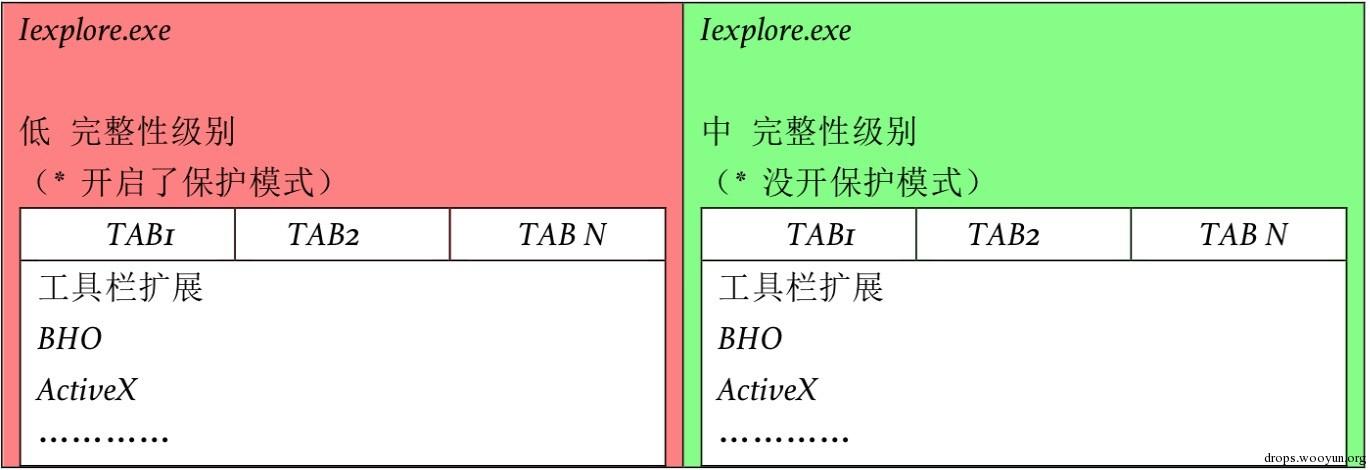
可以看到的是这个版本中 IE 的 UI Frame 和一些管理功能所在的进程运行在中完整性级 别上,而保护模式下,Tab 和网页进程运行在低完整性级别中(禁用保护模式的域下依然是 中完整性级别)。
如上,HTML 和 ActiveX 控件都在网页进程里面,还有一个比较特殊的是工具栏,它也 在网页进程里面。
采用这种模式的好处都有啥?首先是每个 TAB 都独立出去了,其中一个崩了也不会影 响其他的;至于把 UI Frame 移动到了代理进程那边,理由是加快启动速度。
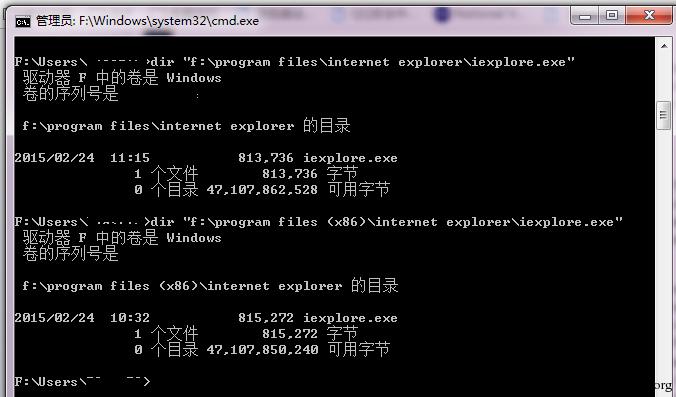
而且由于采用了网页分进程的模式,所以不同完整性级别的网页、tab 都可以归属于同 一个 UI Frame,管理起来也比较方便。 如果你使用过 morden ie,metro ie,你会发现也许它的网页进程都是 64 位的,这是因为 这个版本中啥插件都不加载。即使现在许多插件都有 64 位版本了,比如 Adobe Flash Player, 但是如果一味的追求 64 位化还是会导致各种插件不兼容。 所以在 IE10、IE11 的 64 位版本中,浏览器的 UI Frame 以 64 位运行,而网页进程为了保 证插件的兼容性,所以依然默认采用了 32 位进程。即使你打开的是 64 位的 ie,最后网页进 程还是 32 位的。
所以,也许你会看到有 64 位的 IE 和 32 位 IE 同时存在你电脑里面的样子:
以及,启动 IE 后出现一个 64 位进程和 n 个 32 位进程的样子:

图: IE11 64bit Frame 进程和 32bit Content 进程
相对于 IE7 的模式,可以看出来 IE11 中,即使你手动执行两次 iexplore http://www.wooyun.org , 出来的也仅仅只有一个 64 位的 UI 进程。
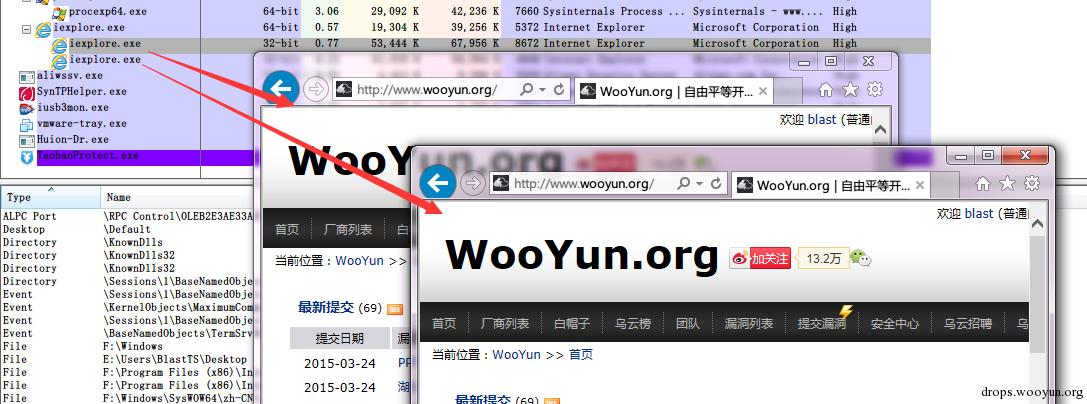
图:IE11 的进程模式
当然,如果你开启了增强保护模式,那网页进程也会变成 64 位的。
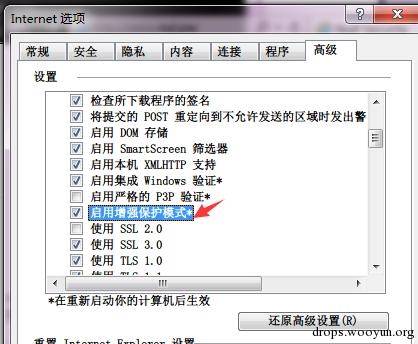
图:IE11 启用增强保护模式
在 Windows 7 下开启这个模式,唯一一个用处就是把进程变成了 64 位,但是 Windows 8 下则会引入 AppContainer 这个进程隔离模式,具体的可以参考参考资料(1)。
限于篇幅,与之相关的内容之后再叙述。
I.3 重要概念:什么是 Markup Service?
回到 IE 的核心功能上来,作为网页的渲染器,超文本标记语言 HTM(Markup)L 想必 是离不开 Markup,那这个 Markup 到底是什么呢?历史上来说,Markup 其实是给演员看的, 简单的说就是剧本,通常还会给它画一道蓝色的标记,标明这个东西应该谁怎么演才合适, 在浏览器中,Markup通常可以看作是一个个的标签。关于Markup Service的内容,建议大 家最开始只了解个大概即可。

图:Markup Script,当然,这个是演员用的,图像来自Google Image
图:IE 可以识别的 Hyper Text Markup Langauge
例如,一个 HTML 文件可能有如下内容:
<DIV>blast<DIV>off
当浏览器解析这个文本时,浏览器会对内容做一次标准化(我比较习惯这么称呼),之 后,DOM 内容看起来像是:
<HTML><HEAD><TITLE></TITLE></HEAD><BODY><DIV>blast<DIV>off</DIV></D IV></BODY></HTML>
这个过程你可以自己去网页 DOM 看:
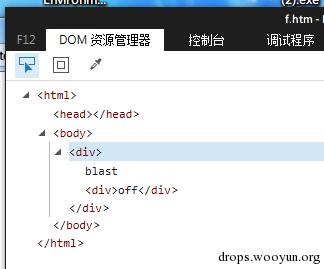
图:IE11 的文档标准化
由于有元素的插入,因此这一项功能可能会引入额外的安全风险,例如我之前发的:
http://wooyun.org/bugs/wooyun-2010-033834
或者可以说,解析器经过这一轮后,将 HTML 文本转为了元素。而且为了内容的完整, 有一些原来没有的元素也加进去了,例如 html、head、title、body 会自动的被解析器构造出 来。
同时,解析器遇到第二个 div(分块)的时候,会自动的把第一个 div 给封闭起来(怎 么封闭要取决于浏览器的实现)。还有之前加入的必要(但是你没写)的标签,比如<html>、<body>,都会自动的被 IE 添上并封闭。
第二个需要注意的概念是 tree 和 stream(树、流)的区别,比如:
This <B>is</B> a test
这组“this is a test”和一对 b 标签的例子,将会被转化为如下的树。text 被当为树叶,element 被作为内节点。
ROOT
|
+-------+--------+
| | |
"this" B "a test"
|
"is"
把文档转为tree之后,所有的操作都会变为类似对树的操作,例如增删子节点。提供此类操作的API被称为Tree Service。
当然,自IE4.0之后,元素的模型操作比简单的树更强悍,比如这个例子:
An <B>exmaple <I> of </B> elements </I> cross
B、I的范围互相交叉,在HTML里面这个很常见,用树来描述则十分困难。因此,Markup Services对这个内容不再提供类似树的操作,而是为方便控制内容暴露了一个基于流操作的模型。

图:相互交叉的范围
因此,Markup Service 它的作用实际上是用来避免产生这种让人觉得迷惑的模型层间的。
当无法用 Tree Service 时,浏览器就转而使用 Markup Service 来控制基于流操作的模型。
在基于树的模型中,网页内容被当作树的节点来处理,每个元素,或者一块 Text 都是 一个节点。节点通过这种类似对树的操作方式来操作,例如从父节点中增删一个子节点。
在基于流的模型的内容操作方式中(比如通过 Markup Service 来操作),文档的内容会 通过使用类似迭代器的对象来操作。 这个就像是在处理上面那个元素交叉的例子一样,这 些带有部分重叠的元素通过两个 Markup Pointer 来区分,每个 Markup Pointer 指定着 Tag 从 哪儿开始,Tag 到哪儿结束。所以,基于流的模型是基于树的模型的一个超集。
说了这么多,要引入我们的 Markup Pointer 了。在这之前,举一个类似的例子,C++中, 比如如果要操作一个 vector,使用迭代器是非常方便的做法:
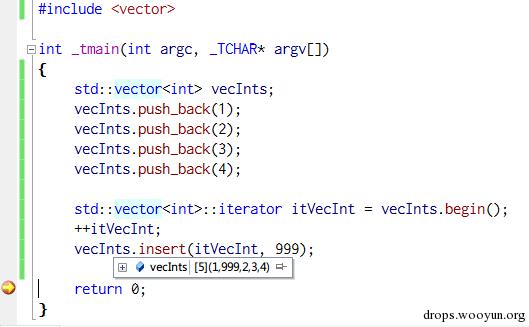
图:使用迭代器向 vector 插入一个元素
也如你所见,Markup Pointer也有些许神似迭代器。可以通过创建和操作无效文档的过程来理解一下。
注意之前“This is a test”的例子,浏览器可能都不会被认为这是一个有效的 HTML 文档。
最小的有效HTML文档至少要有html、head、title和body四个元素,当你提供的内容中没有这些元素时,解析器会自动建立,然后把它们放到合适的位置上。
在文档解析过程中,使用Markup Service即可删除或者重新排列DOM。例如,你可以整块删除html、body元素。你可以把head移动到body里面(但是这么做的话,文档会被当作是无效文档)。
在IE中,提供这个服务的类有很多,最普遍的类即CMarkup,负责“指向元素、区域”的Markup 指针类名字是CMarkupPointer,它们都派生自CBase。
如果有关注类似的内容的话,之前发的一个CMarkupPointer空指针引用的问题其实就与这相关(http://wooyun.org/bugs/wooyun-2010-079690 )。
关于 CMarkupPointer,有一些需要注意,也是可能会导致 IE 崩溃或者出其他错的问题,
分别是:
(1) Markup Pointer 刚创建,或者以一个无效对象为构造函数的参数创建的时候是未指 向状态,也就是说啥都没指,通常这个值是 0,这个很可能会导致空指针引用;
(2)Markup Pointer 设置了指针粘滞(当当前指针所在区域发生移动之后,区域内的指 针是否也跟着计算新位置)的时候,如果同时也设置重力(重力分为左右重力, 简单来说,就是在指针处插入一个内容,操作完之后,指针是应该贴着左边的内 容还是右边的内容),且在经过某些操作后发生了歧义,在对 Markup Pointer 指向的部分进行移动、删除过程后,Markup Pointer 有可能会重新变成未指向状态。这是因为指针指向的内容不存在或无效了,指针已经从文档中移除(注意是 remove)了,但是指针自身还没有被删除(delete),以后如果重用这个指针又没做 校验的话,很可能就会出事儿。
(3)Markup Pointer 左右移动的时候也有可能移动出错。
还有就是一个经验条例,IE 中代码很依赖比较上层的有效性检查,所以一旦中底层代码接收到了无效数据,IE 就很可能会出现异常。
还是重提一下关于Markup Service的内容,如果之前没接触过的话,最开始只了解个大概即可,之后等了解了更多IE相关的内容时,这一块的东西才容易和其他部分联系起来,只是这个属于基础性的设施,所以才放在比较前面来介绍,老实说最开始我看这个东西感觉也是相当的头疼……所以看着比较迷糊的话也不用太在意,有个印象就可以了。
参考资料
(1)腾讯反病毒实验室:深度解析 AppContainer 工作机制
(2)Q&A: 64-Bit Internet Explorer